
こんにちは、ミントです
オブジェクトを使うと、数値や文字などを再利用することができました
オブジェクトをきちんと扱うには、オブジェクトの「データ型」を意識することが大事でした
今回は、データ型を意識する例として、定性的データ(カテゴリカルデータ)分析でやる処理を考えてみましょう
本記事の概要
定性的データってなに?
定性データというのは、(男・女)や、(りんご・みかん・バナナ)のような、数値ではなく、カテゴリーなどを表現したデータのことをいいます
また、定性データを区別する基準(男・女など)のことを「要因(Factor)」といいます
要因を含むデータについて統計分析するには、そのまま処理するわけではありません
要因は文字で表現されたものが多いので、文字を数値にして処理します。これをデータの前処理といいます
今回は定性データ分析で必要となる前処理をしながら、データ型がどう変わっているかをみてみたいと思います
まず、要因を表現するデータをつくります
りんご・みかん・バナナというデータを、kudamono というオブジェクトに代入しています

この「 c ( ) 関数 」というのは、複数のデータを一括してまとめて定義する関数です
りんご、みかん、バナナは全角文字で、その他は半角文字ということに注意してくださいね
c ( ) 関数については、おいおい説明しますので、今回は、「りんご・みかん・バナナ」をオブジェクトに代入できたことがわかってもらえばオッケーです 🙂
オブジェクトの型を調べてみる
では、このkudamono オブジェクトの型を調べてみましょう
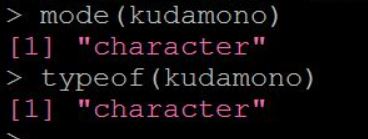
すると、このデータ型は character ということがわかりました
このkudamono オブジェクトを、「 factor( ) 関数 」で処理します
factor () 関数をつかった変換した結果を、kudamono2 オブジェクトに代入しています

kudamono2 オブジェクトのデータ型を調べてみると、numeric になっています!(先ほどは、character でしたね)
そして、データの内部表現は、 integer になっています
つまり、factor( )関数をつかうことで、character だったものが、numeric になりました。
これで数値処理しやすくなったわけです
また numericの内部表現は整数型となっています
オブジェクトの中身を調べてみる
kudamono2 の中身の情報を、「 str () 関数 」をつかってみてみましょう

すると以下のように、要因(Factor)が3つのレベル(levels)になっていて、
バナナ・みかん・りんご(りんごは略されてますが)の順に、3,2,1という整数が割り当てられて表現されています
このように、定性データ分析では、要因をfactor() 関数で数値に変換してから統計処理されます
統計解析では、オブジェクトのデータ型を正しく変換しておかないと、思わぬエラーを招いてしまうことがあるわけです
わかりやすさのために省いていましたが、データ型を確かめるには、「 class () 関数 」も使えます

class () 関数を使うと、kudamono2 のデータ型は、factor型と表示されます
あれ!?mode()関数をつかうと、numeric型だったのにな??
って思われた方するどいです!
同じオブジェクトのデータ型でも、目的に応じて、表現の仕方を選んで調べることができるのです
- mode (), typeof () は、コンピュータの仕組みに近いデータ型
- class( ) は、統計解析をするときに意識するデータ型
のような違いがあるのかなぁと思っています
調べたい目的によって、使い分けてみましょう~
というわけで、今回は、オブジェクトのデータ型を意識しておく例として、 factor () 関数での変化をみてみました。
Rには、「作業ディレクトリ」というのがあります。
ファイルを扱ったりするなら、必須です↓

