
こんにちは、ミントです
今回は、Rに標準で備わっているデータ構造の4つめ、「データフレーム」を使ってみたいと思います
「 データフレーム 」は、これまでのベクトル、行列、配列と決定的に違う点があります
それは、データフレームの各要素は、データ型が異なってもいい、ということです
ベクトル、行列、配列では、データの次元が変わるだけで、要素のデータ型はすべて同じである必要がありました
データフレームにはこの制限がありません
なので、現実に出くわすデータを扱うのにとても都合のいいデータ型です
ここでは、データフレームを生成させて、要素を操作する方法を学びましょう
本記事の概要
データフレームを生成してみる
今回作成するデータフレームは、以下の表にしてみます
| 名前 | 性別 | 血液型 | 身長 | 体重 |
| Aくん | 男性 | A | 175 | 69 |
| Bさん | 女性 | B | 162 | 51 |
| Cさん | 女性 | O | 145 | 42 |
| Dくん | 男性 | A | 170 | 65 |
| Eくん | 男性 | AB | 183 | 83 |
この表には、文字型と数値型のデータが混在しています
これをR上に生成してみましょう
データフレームの生成には、data.frame ( ) 関数をつかいます
ここでは、data というオブジェクトにデータフレームを代入しています
データフレームの内容は、Aくん、Bさん、Cさん、Dくん、Eくんの5人について、5つの属性(名前、性別、血液型、身長、体重)が含まれています
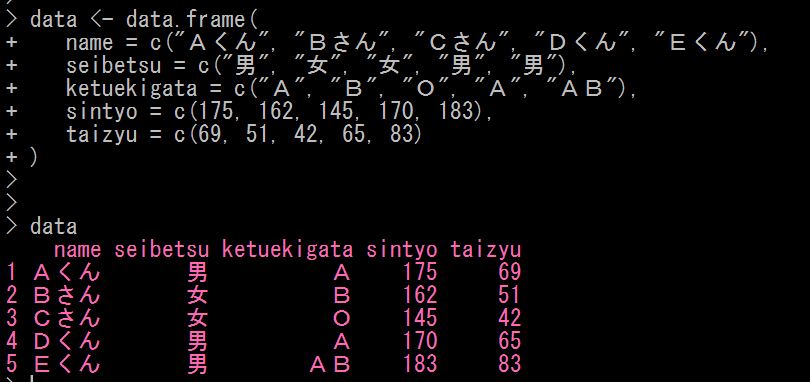
ピンク文字のデータフレームができました
データフレームの中身を確認する
データフレームなどのオブジェクトの中身は、「 str ( ) 関数 」をつかって確認すると便利です
str ( オブジェクト名 ) という形でつかいます
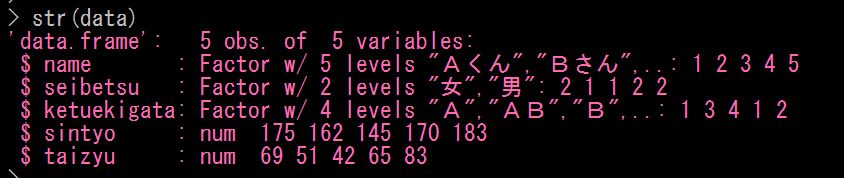
ピンク色の内容は以下になります
1行目: データフレーム型であり、5人について、5つの変数(属性)があることを示しています
2行目: 変数名($)が name で、中身はファクタ型 ( Factor )で、5つのレベル(AくんからEくんまで)があることを示しています
3行目: 変数名が seibetsu で、ファクタ型、2つのレベル(男女)があることを示しています
4行目: 変数名が ketuekigata で、ファクタ型、4つのレベル(A, B, O, AB)があることを示しています
5行目: 変数名が sintyo で、数値型 ( num ) で、5つの数値が示されています
6行目: 変数名が taizyu で、数値型、5つの数値が示されています
このように、str ( ) 関数を使うと、オブジェクトの中身が整理された形で確認することができ便利です
データフレームの要素を取り出してみる
統計分析では、データフレームのデータを自在に操れるとうれしいです
データフレームの中の必要な要素を指定して、取り出してみましょう
まず。Aくんの血液型を取り出してみましょう
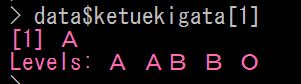
data オブジェクトの変数 ( $ ) 血液型 ( ketuekigata ) の 1 列目を表示するよう指定しています
これを、 data $ ketuekigata [1] と書いているわけです
他の取り出し方もあります
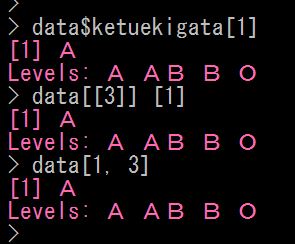
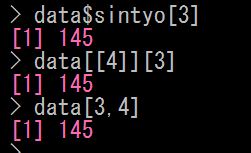
2つ目のやり方では、data [[ 3 ]] [ 1 ] としています
1つめの $ketuekigata を [[ 3 ]] で表現しています
3つめのやり方では、data の1行3列の要素を [ 1, 3 ] と指定しています
Cさんの身長を取り出してみましょう
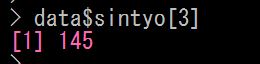
data オブジェクトの変数 sintyo の3列目を表示してください、とすればいいわけです
同じように、こんな指定のしかたもできます
これでデータフレームの作成と、要素の取り出しができるようになりました
というわけで、今回はデータフレームの操作の前半をやりました
後半では、データフレームの一部分を抽出したり、データフレームにデータを加えたりしたいと思います
データ分析でもよく使う、データの部分抽出を、Rでやってみました↓

